Stable Diffusion is a powerful tool for image generation, but there's so many ways you can use it, and so many add-ons that it's difficult to know where to start.
This series is for you if you've heard of Stable Diffusion and have a general idea of what it's capable of, but have no idea how to get started.
This is Part 1 of the Stable Diffusion for Beginner's series:
Part 1: Getting Started: Overview and Installation
Part 2: Stable Diffusion Prompts Guide
Part 3: Stable Diffusion Settings Guide
Part 3: Models
Part 4: LoRAs
Part 5: Embeddings/Textual Inversions
Part 6: Inpainting
Part 7: Animation
What is Stable Diffusion?
Stable Diffusion is an image generation model that was released by StabilityAI on August 22, 2022.
It's similar to other image generation models like OpenAI's DALL·E 2 and Midjourney, with one big difference: it was released open source.
This was a very big deal.
Unlike these other models—which were closely guarded by the companies that made them—anyone could customise Stable Diffusion or build on top of it.
In the short weeks that followed the release there was an explosion of innovation around Stable Diffusion.
The best part is you can run it on an ordinary computer.
Is it free?
Yes, Stable Diffusion is free.
There are many paid tools and apps out there that make it easier to use Stable Diffusion. These have their own pros and cons.
Is it the most popular image generation tool?
Stable Diffusion is the second most popular image generation tool after Midjourney.
Many predicted that Midjourney would overtake Stable Diffusion as the most popular AI image generation tool at the end of 2022.
That prediction has come true: Midjourney has surpassed Stable Diffusion on a number of different metrics, including search volume and social media engagement.
Compare the growth of the Midjourney subreddit to that of the Stable Diffusion subreddit:
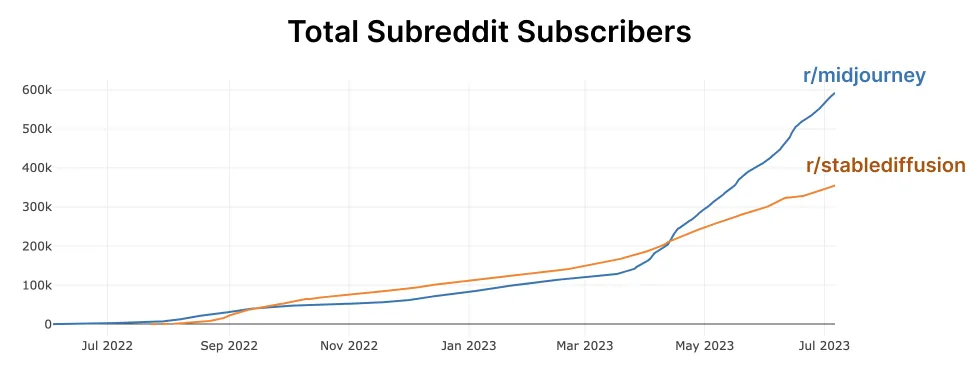
We attribute this to Midjourney's viral spread through social media, the high quality images of Midjourney V4 and subsequent models, and its ease of use. It's also benefited from increased Discord adoption.
This is not an apples-to-apples comparison.
Most image generation tools, such as Leonardo AI use Stable Diffusion models under the hood to produce their images.
You could argue that Stable Diffusion is more impactful than Midjourney because of how many new tools and technologies rely on it.
What can you do with Stable Diffusion?
Generate images from words
This is the most common use of Stable Diffusion. It's called text-to-image (txt2img) because you enter type and get an image back.
Today, you can generate images in an incredible amount of styles.
Realistic



Semi-Realistic



Anime
Learn how to create anime images.



Game Assets

Landscapes

Generate images from existing images
You can use existing images as stylistic inspiration to create new images, or transform them in many different ways.


Fix and edit images
You can paint over images, and regenerate the painted over part to be exactly what you want. This is called inpainting.


Paint and generate at the same time
You can take inpainting to the extreme:
Extend images
You can even generate outside the frame to extend images. This is called outpainting.
Create animations
There are a number of different methods to create animations with Stable Diffusion. The most popular is Deforum, which creates these very trippy animations:
Best way to run it?
Everybody has different aspirations and different technical limitations so there are a number of ways to run Stable Diffusion.
Online Apps
There are a number of websites that you can run Stable Diffusion on, both free and paid.
Here's a free demo you can try, by StabilityAI (creators of Stable Diffusion):

ArtBot is another good free website to test out. It works great on mobile, and has a bunch of models and features: img2img, inpainting and a public gallery.

Mobile Apps
So far the best mobile app we've tried is Draw Things by Liu Liu.
Run on your own computer
If you want to become an intermediate user you will want to run Stable Diffusion on your own computer. This will get you the most features and customizability.
To do this, you'll need to download a User Interface.
I recommend AUTOMATIC1111's Stable Diffusion WebUI. It's by far the most popular Stable Diffusion user interface, with over 60k likes on the Github repo.
Here are the installation instructions:
Running in the Cloud
This is a little bit different from the online versions mentioned earlier. You are running the full User Interface, however you are using Google's servers to do this.
You get access to all the features, but don't have to use your own computer.
Google Colab is a service that allows you to run Python code, but on Google's servers.
It might seem intimidating if you've never coded before, but it's really just pressing a series of "run" buttons to execute different sections of code.
- TheLastBen's Fast Stable Diffusion: Most popular Colab for running Stable Diffusion
- AnythingV3 Colab: Anime generation colab
Important Concepts
Checkpoint Models
StabilityAI and their partners released the base Stable Diffusion models: v1.4, v1.5, v2.0 & v2.1.
Stable Diffusion v1.5 is probably the most important model out there.
That's not because it makes good images, but because it's been used to train so many custom models.
Today, most custom models are built on top of either SD v1.5 or SD v2.1. These custom models are what you want to use when you're trying to generate high quality images
Checkpoint models come in the old file format .ckpt (checkpoint) or the new file format .safetensors.
Check out: Most popular Stable Diffusion models




The story behind anime models is a bit different. Most anime models trace their lineage to NAI Diffusion, created by the company NovelAI (and offered as a paid service on their website). Similar to Stable Diffusion v1.5, nobody uses NAI Diffusion to generate images anymore, only to train new LoRAs (more on that in a bit) and models.
Check out: Most popular Stable Diffusion anime models




VAE
Without Vae your images will look washed out. Vae are the separated color training of a checkpoint model; most models have a recommended vae but vae's are interchangeable, so you can use your favorite one with a variety of different checkpoints.
LoRA
A LORA is a Low Rank Adaption file it adds new concepts and terms to your AI that weren't originally built in. This is where a persons customization can really be seen. Lora's are applied at a percentage to your checkpoint to add their individual training to the checkpoint in use.
Improving your results
Prompting
Think of prompting as learning a new language that effectively communicates to the AI what output you want.
Here's an example of a prompt (the negative prompt is what you don't want):

MODEL:
Prompt:
((face)), (rogue thief:1.2) female wearing (leather armor:1.2),
(white silk cloak), (fabric with intricate pattern:1.2), (insanely detailed:1.5), (highest quality, Alessandro Casagrande,
Greg Rutkowski, Sally Mann, concept art, 4k), (analog:1.2), (high sharpness), (detailed pupils:1.1), (painting:1.1), (digital
painting:1.1), detailed face and eyes, Masterpiece, best quality, (highly detailed photo:1.1), 8k, photorealistic, (young woman:1.1), By jeremy mann, by sandra chevrier, by maciej kuciara, sharp, (perfect body:1.1), realistic, real shadow, 3d, (asian temple background:1.2), (by Michelangelo)Negative Prompt:
easynegative badhandv4This is a long prompt, but a prompt very short and simple too:

MODEL:
Prompt:
(best quality)), ((masterpiece)), (detailed), woman sitting at table, Claude MonetNegative Prompt:
badhandv4Here are some general prompting tips:
- Make user of quality tags like "masterpiece" and parentheses to emphasize your tags.
- Different models respond differently to prompting styles. Choose a few models you love and stick with them to learn the ins-and-outs of their prompting, instead of feeling like you have to download every model.
- Use artists names. Specifically, use artists names that are well represented in Stable Diffusion.
- The fastest hacks to improve your generations? Use LoRAs and Embeddings.
See the Stable Diffusion prompting guide for more.
Next steps
You're done with Part 1!
Part 1: Getting Started: Overview and Installation
Part 2: Stable Diffusion Prompts Guide
Part 3: Stable Diffusion Settings Guide
Part 3: Models
Part 4: LoRAs
Part 5: Embeddings/Textual Inversions
Part 6: Inpainting
Part 7: Animation

