Your choice of Stable Diffusion checkpoint model determines what type of images you will generate.
There are so many models out there it's quite hard to keep track.
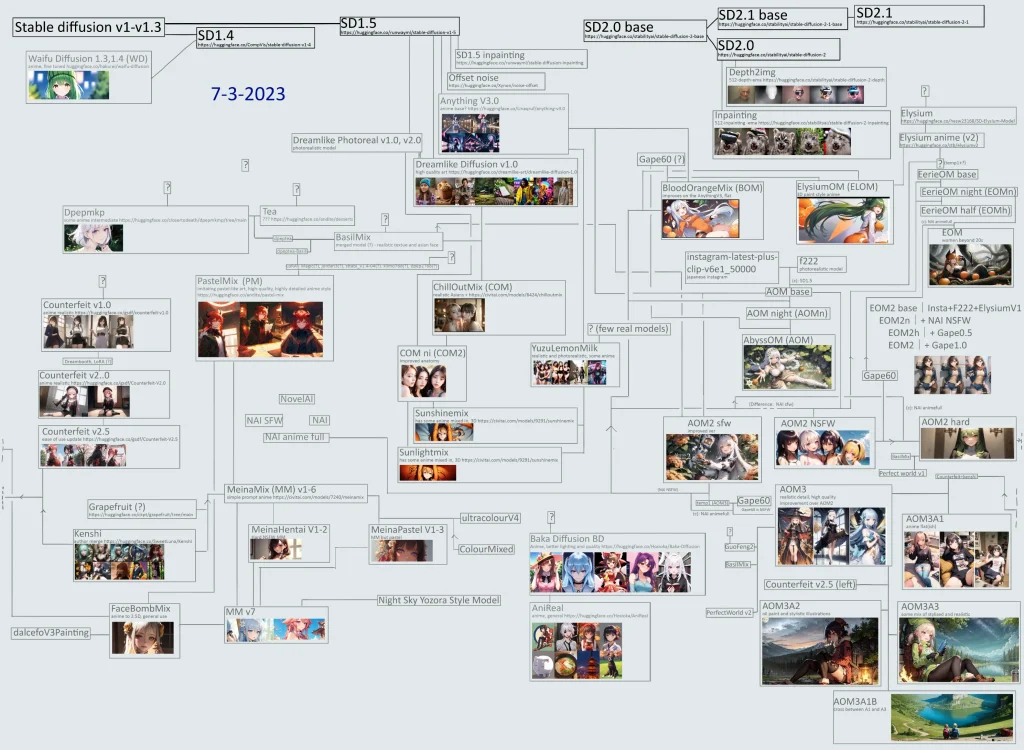
I did a comparison of the top anime models today, using the most popular models/the models with the most social media mentions.
You might also be interested in these general-purpose/realistic models.

Quick summary:
- Counterfeit and PastelMix are beautiful models with unique styles. Very easy to get good results with. I would highly recommended any of these for your first model.
- NAI Diffusion is an important model because it's used to create so many other anime models. Though historically significant, it's a bit dated and it shows.
- Anything models are finetunes of NAI, that improve the image quality and details
- OrangeMix series is very popular in the Japanese community. They usually merge Anything V3 + NAI Diffusion + other anime models.
- AbyssOrangeMix3 is a mix of a lot of anime models, it stands out because of realistic, cinematic lighting

Stable Diffusion Anime: A Short History
StabilityAI released the first public checkpoint model, Stable Diffusion v1.4, in August 2022. In the coming months they released v1.5, v2.0 & v2.1. In July 2023, they released SDXL.
Soon after these models were released, users started to fine-tune (train) their own custom models on top of the base models.
NAI Diffusion is a proprietary model created by NovelAI, and released in Oct 2022 as part of the paid NovelAI product. The architecture was a modified version of the Stable Diffusion architecture.
The model was leaked, and fine-tuned into the wildly popular Anything V3.
People continued to fine-tune NAI and merge the fine-tunes, creating the ecosystem of models we know today.
Usage
Running locally
To use different SD models, you just have to download them as well as the AUTOMATIC1111 WebUI to run them with. Installation instructions for different platforms:
Google Colab
You can run the WebUI in the cloud with Google Colab. Before this was free, however Google Colab has updated its rules. Now you must pay $10/mo for Google Colab Pro to run Stable Diffusion.
Under each model, you can click on Links -> click on Open in colab link.
To use Colab, open one of these notebooks, then click Runtime -> Run all. After a few minutes your WebUI will be ready, and you will get a message like this:
Running on local URL: http://127.0.0.1:7860
Running on public URL: http://973c3956-5540-4671.gradio.live
You can use either URL.
Using an anime generator website
There's a number of websites that let you try the models in this article for free. Some of them have very generous free plans.
Check out this list of anime AI generators.
Model Comparison
These all use the exact same prompt and settings.















Prompt:
masterpiece, best quality, kisaragi chihaya, solo, 1girl, ((musical notation)) vector background:0.2], anime, idolmaster, singing, long blue hair, brown eyes, idol, knee length skirt,white shirtNegative prompt:
deformed, blurry, bad anatomy, wrong anatomy, disfigured, distorted, poorly drawn face, poorly drawn hands, strangely bent, bad proportions, mutation, mutated, malformed, (out of frame), watermark, signature, text, bad art, beginner, amateur, low quality, worst quality, EasyNegativeSettings:
- Sampler:
Euler A - Size:
512x768 - Steps:
20 - CFG scale:
7 - Clip skip:
2 - Seed:
324646734167 - Batch Size:
1
Models List
NAI Family
NAI Diffusion



NAI Diffusion is a model created by NovelAI.net by modifying the Stable Diffusion architecture and training method. It is sometimes called animefull, because of its filename.
At the time of release, it was a massive improvement over other anime models. Whilst the then popular Waifu Diffusion was trained on 300k anime images, NAI was trained on millions.
Here's a NAI prompt guide that is broadly applicable to most anime models.
Most popular models today can trace their lineage to NAI in some way.
Anything V3



Download Link • Model Information
Created by a Chinese anon, Anything V3 was released to immediate popularity.
It was a fine-tune of NAI that improved on details, shading and overall quality.
While Anything V1 & V2 exist, they never reached the worldwide popularity of V3, and are difficult to find outside of Chinese forums.
Anything V5



Download Link • Model Information
(The Anything creator gave up on Anything v4 and v4.5. The v4 and v4.5 models that are published today are considered "fake", as they were made by another person and have a very different aesthetic.)
In the creator's own words, V5 is more faithful to prompting than V3. As such, more prompting skill is required for good looking images. The creator actually recommends beginners use V3, because they will likely get better looking images.
OrangeMixes
AbyssOrangeMix2 (AOM2)



Download (SFW Variant) • Download (NSFW Variant)
Model Information
AbyssOrangeMix2 (AOM2) is a model for creating high-quality, highly realistic illustrations.
Recommended Sampler: DPM++ SDE Karras
AbyssOrangeMix3 (AOM3)


Download Link • Model Information
Latest version of AOM.
Counterfeit



Download Link • Model Information
High quality anime model with a very artistic style. Created by gsdf, with DreamBooth + Merge Block Weights + Merge LoRA. Highly recommended.
MeinaMix



Download Link • Model Information
High quality anime model with a very artistic style. Created by gsdf, with DreamBooth + Merge Block Weights + Merge LoRA
PastelMix



Download Link • Model Information
High-chroma, vivid painterly style, influenced by Pastel art. Highly Recommended.
Tips
Use LoRAs
You use LoRAs in addition to the checkpoint models above to add stuff to them.
For example, you could use an Studio Ghibli LoRA to make your outputs look more like the Studio Ghibli aesthetic.
The Best Stable Diffusion LoRAs
Use Negative Embeddings
Here's a super fast way to fix things like bad hands and bad quality images:
Use negative embeddings in your prompts.
Embeddings (AKA Textual Inversion) are small files that contain additional concepts. You activate them by writing a keyword in the prompt.
Negative Embeddings are files trained on bad quality images. By placing these in the negative prompt, you'll get better quality images.
Some popular negative embeddings are EasyNegative and negative_hand.
FAQ
Many custom checkpoint models also come in different file sizes: fp16 (floating-point 16, aka half-precision floating-point) and fp32 (floating point 32, aka full-precision floating-point). This refers to the format in which the data are stored inside the model, which can either be 16-bit (2 bytes), or 32-bit (4 bytes). Unless you want to train or mix your own custom model, the smaller (usually 2 GiB) fp16 version is all you need. For most casual users, the difference between the image quality produced by fp16 and fp32 is insignificant.

