When I got started with Stable Diffusion, I was frustrated that my images didn't look anything like the ones I saw on social media.
If you feel that way, this guide is for you.
It will cover the ins-and-outs of basic prompting. I'll go through things like:
- Basic prompt template
- The truth behind negative prompts
- Prompt weights
- Prompt order
- High-level tips and techniques
Prior to reading this guide, I recommend reading Stable Diffusion Recommended Settings for Beginners.
Why? Because most people starting out will get more improvements out of optimizing their settings, rather than optimizing their prompts.
This combined knowledge of prompts and settings will be enough to push your skill to the top 10% of Stable Diffusion users.
Let's dive in!
Prerequisites
You should have installed AUTOMATIC1111's Stable Diffusion WebUI locally or set it up on your favorite cloud GPU service.
Here are the instructions for local installation based on platform:
If you prefer (or have to) to run in cloud:
Regardless of how you've installed AUTOMATIC1111, you'll see the same interface when you run it:
This guide will make use of both the ReV Animated and DreamShaper models. These are highly versatile models, and the takeaways we get here will be applicable to many other models as well.
Even though the models are SD v1.5 based, the insights here are broadly applicable to SDXL models.
Prompts: Getting Started
Prompts are the words you give to the AI to tell it what to generate.
Here's a very simple prompt template to get started. It all begins by asking: what do you want to see?
- What's the subject? eg. →
girl - What are the attributes of the subject? →
looking to side, jeweled crown - What are the visual characteristics of the image?
- Camera Angles / Camera shot type →
close-up - Lighting →
cinematic lighting, ethereal glow - Art Styles / Artist Style / Aesthetics →
digital painting - Color Scheme →
vibrant colors - Surrounding Environment →
in a forest
- Camera Angles / Camera shot type →
- Descriptors of quality (explained below) →
best quality, masterpiece
Put those all together:
girl, looking to side, jeweled crown, close-up, cinematic lighting, fantasy art, digital painting, ethereal glow, vibrant colors, forest, best quality, masterpieceYou'll want to try out different models to see which one you like the best. Here's the prompt above being used with my favorite models:




Quality Tags
A lot of people use "quality tags" in their prompt, which are words and phrases like:
- masterpiece
- best quality
- intricate details
These words will have a positive impact on most prompts. How great the impact depends on the model you're using.

girl looking to side, jeweled crown, close-up, cinematic lighting, vibrant colors, fantasy art, disney pixar style, ethereal glow, forest
((masterpiece)), (top quality), (best quality), girl looking to side, jeweled crown, close-up, cinematic lighting, vibrant colors, fantasy art, disney pixar style, ethereal glow, forest
A general rule of thumb: the more "anime-oriented" a model, the better these tags will work.
Negative Prompts
There's a lot of confusion behind negative prompts, because there are so many different ways people think about how to use them. Here are 2 of the most common ones:
- Undesirable content: Negative prompt should be what you don't want in the image, eg. "bad hands" "mutated"
- Conceptual opposite: Negative prompts should be the conceptual opposite of your prompts, eg. "noodles" if you're trying to generate "rocks", "anime" if you're trying to generate "photorealism"
Even though the latter is the "correct" way to think about negative prompts, the former can be practical.
Negative prompts don’t work in the sense you are telling the AI to fix your deformed hands. Rather, they provide a direction (vector) that moves the generation away from the part of latent space that has a likelihood of containing those things. Think of prompts and negative prompts as locked into a game of tug-of-war.
Undesirable Content Negative Prompts
Here's an image that came out well that makes use of a simple negative prompt using the ReV Animated model:
(1girl) looking at camera, braids, smiling, dress, rural envionment, lens flare, beautiful day (fabric with intricate pattern:1.2), (insanely detailed:1.2), ((masterpiece)), (painting:1.1), (digital painting:1.1)
Negative prompt: cartoon, 3d, ((disfigured)), ((bad art)), ((deformed)), ((poorly drawn)), ((extra limbs)), ((close up)), ((b&w)), weird colors, blurry
Steps: 35, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 561242768, Size: 768x512, Model hash: 4199bcdd14, Model: revAnimated_v122, Denoising strength: 0.7, Hires upscale: 2, Hires steps: 15, Hires upscaler: 4x-UltraSharp, Version: v1.4.1
Negative prompt: cartoon, 3d, ((disfigured)), ((bad art)), ((deformed)), ((poorly drawn)), ((extra limbs)), ((close up)), ((b&w)), weird colors, blurry
Take a look at what happens if I increase the length of the negative prompt, adding lots of "undesirable content".

Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), (b&w:1.2), (black and white:1.2), (blurry:1.2), (out of frame:1.2), (ugly:1.2), (cross-eyed:1.2), (disfigured:1.2),(deformed:1.2), (extra limbs:1.2), (b&w:1.2), (blurry:1.2), (duplicate:1.2), (morbid:1.2), (mutilated:1.2), (poorly drawn hands:1.2), (poorly drawn face:1.2), (mutation:1.2), (deformed:1.2), (bad anatomy:1.2), (bad proportions:1.2), (watermark:1.5), (text:1.5), (logo:1.5)
The image is crisper, shadows are deeper, and the character is more animated and less stiff.
Conceptual Opposite Negative Prompts
StabilityAI published a promptbook a while ago. Many readers noticed the negative prompts were completely unhinged.
An "opposite" may not make much sense to us, but make sense in the context of latent space. Check out this experiment.
One way to find out the opposite of your image: use a negative CFG scale.
AUTOMATIC1111 does not allow a negative CFG scale. However, we can get around this using the X/Y plot feature (a very handy feature in other situations that lets you create comparison plots with different settings).
Go to the bottom of the screen. Below the Seed field you'll see the Script dropdown. Select X/Y/Z plot, then select CFG Scale in the X type field. Write -7 in the X values field.
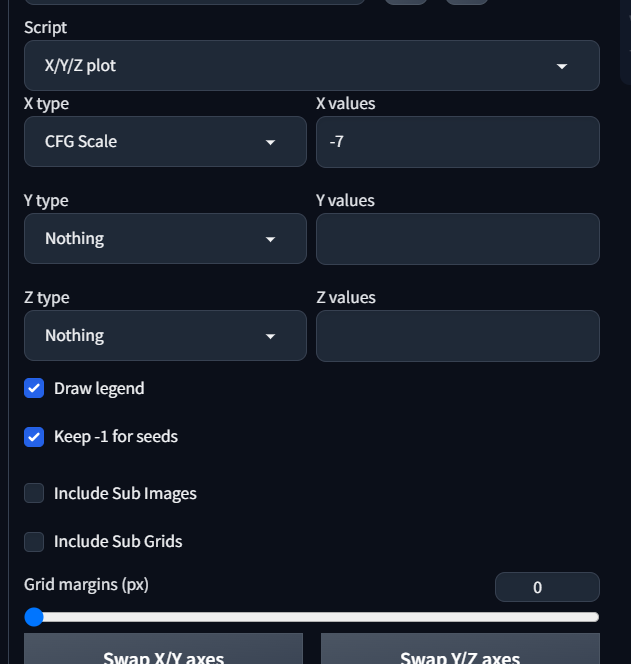
Now when you generate, you'll be getting the opposite of your prompt, according to Stable Diffusion. Here's what I got:

Apart from being extremely unsettling, these images have a lot in common!
I identify the commonalities and use them in a new negative prompt. If you're finding it hard to describe images, try using them CLIP Interrogator, which will tag them for you.
Here's the final result:

a black and white photo of a cartoon character, greyscale, zbrush, (ambient occlusion render), b&w, (photo of a man's torso), polycount, sculpture, (ugly:1.2),(bad quality:1.2)
Takeaways:
- Very long "undesirable content" prompts are mostly placebo. See this Reddit post.
- "Undesirable content" prompts work because they are still pushing the generation away from concepts in latent space
- Opposite prompts can produce very interesting results.
Changing the style with negative prompts
Here's an underappreciated use of negative prompts. Describe styles that are the opposite of the style you want.


Weights with Parentheses
Parentheses
In Stable Diffusion, parentheses are used to increase the weight of (emphasize) tokens, such as: (((red hair))).
The default weight of a token is 1.
The weight of anything inside parentheses will be multiplied by 1.05.
This multipler stacks on itself depending on how many parentheses you use:
| Number of brackets | Prompt | Total Strength | Image |
|---|---|---|---|
| 0 | jeweled crown | 1 |  |
| 2 | ((jeweled crown)) | 1.1025 |  |
| 4 | ((((jeweled crown))) | 1.216 |  |
| 6 | ((((((jeweled crown)))))) | 1.340 |  |
| 8 | ((((((((jeweled crown)))))))) | 1.477 |  |
Don't add too many parentheses however, as you'll get to a point where the emphasized word will completely overpower the image.
You can also be specific and write the exact weight you want using the format (KEYWORD:WEIGHT).
So you could write (jeweled crown:1.477), and this would be the same as ((((((((jeweled crown)))))))).
Square Brackets
In Stable Diffusion, square brackets are used to decrease the weight of (de-emphasize) words, such as: [[hat]].
The weight of anything inside the square brackets will be divided by 1.05.
You use it when you still want the concept in the brackets, you just want to diminish it relative to the other concepts.
This is not the same as a negative prompt.
| Number of brackets | Prompt | Total Strength | Image |
|---|---|---|---|
| 0 | jeweled crown | 1 |  |
| 2 | [[jeweled crown]] | 0.907 |  |
| 4 | [[[[jeweled crown]]]] | 0.823 |  |
| 6 | [[[[[[jeweled crown]]]]]] | 0.746 |  |
Notice how the crown gets smaller and smaller, until it dissappears at 6 square brackets.
Word Position
You might have a sense that tokens placed earlier in the prompt are more important than tokens that come later in the prompt.
That's only half the story.
When Stable Diffusion parses your prompt, it does so in chunks. Chunks are processed in order.
Here's a common problem with Stable Diffusion: when you specify the colors of certain objects, they bleed over into other objects. In this one I specified 5 different colors, and it almost got them right, with the exception of the red tie:

1girl, close-up, green eyes, long black hair, white dress shirt, gold earrings, red tieTo solve this, I would move the "red tie" to somewhere else in the prompt, where it will be parsed in a different chunk than the "gold earrings":

1girl, close-up, red tie, green eyes, long black hair, white dress shirt, gold earringsYou can also write "BREAK" to manually separate the parts before and after this word into chunks. The word must appear on it's own line. For example:
1girl, close-up, red tie, green eyes, long black hair, white dress shirt,
BREAK
gold earringsCamera, Lighting & Photography Keywords
Learning some basic photography terms will give you a big leg up. These terms are used extensively in tagging the images and training the models.
Camera Shot Types
Close-up / Portrait
Try the kewords [close-up], [portrait], [face].

MODEL:
Prompt:
close-up, (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), (fractal art:1.2),absurdres, highres, ultra detailed, Ultra-precise depiction, Ultra-detailed depiction, solo, ( halo armor:1.2), dynamic pose, floating hair, (thin: 1.2), (abstract:1.2),
Negative Prompt:
easynegative badhandv4SAMPLER:
DPM+++ SDE Karras
Medium Range
Try the keywords [medium shot], [medium cowboy shot].

MODEL:
Prompt:
medium cowboy shot, (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), (fractal art:1.2),absurdres, highres, ultra detailed, Ultra-precise depiction, Ultra-detailed depiction, solo, ( halo armor:1.2), dynamic pose, floating hair, (thin: 1.2), (abstract:1.2),
Negative Prompt:
easynegative badhandv4SAMPLER:
DPM+++ SDE Karras
Full Body
Try the keywords [full body].

MODEL:
Prompt:
full body, (masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), (fractal art:1.2),absurdres, highres, ultra detailed, Ultra-precise depiction, Ultra-detailed depiction, solo, ( halo armor:1.2), dynamic pose, floating hair, (thin: 1.2), (abstract:1.2),
Negative Prompt:
easynegative badhandv4SAMPLER:
DPM+++ SDE Karras
Depth of field
Depth of field is the area of acceptable sharpness in front of and behind the subject. Put simply, it refers to how blurry or sharp the image is around your subject
High depth of field is used to create intimacy with subjects.
Style Keywords
Here are some interesting keywords to modify the style and their effects.
All of these images use the same prompt, with an added phrase to modify the style:
Prompt:
((best quality)), ((masterpiece)), (detailed), woman sitting at table, <STYLEMODIFIER>Negative Prompt:
worst quality badhandv4 easynegativeArt Mediums / Art Styles








Artist names








Is there a "correct" way to prompt?
Some people will prompt with grammatically correct sentences like [a photograph of a girl wearing a parka in a city] and others will write fragements like [photograph, 1girl, parka, city]. So which way is correct?
Unfortunately the answer is: it depends.
It depends sometimes on the model you're using.
The base 1.5 model by RunwayML and 2.x models by Stability AI are capable of processing natural language commands like the first.
The Novel AI model (leaked, but since incorporated into many of the anime models out there) use comma-delineated tags like the second, based on the Danbooru tagging concept.
When models are blended with both elements, you can use both. And you'll likely get the equivalent results so long as SD can pick out the keywords in there.
Looking for Inspiration
The best places to find prompts right now:
- civitai.com features user-submitted prompts and images for every model
- mage.space lets you explore prompts by genre
- tensor.art lets you explore prompts by subject
- majinai.art is up-to-date on anime models, and is a good place to find anime prompts


Learned a lot from you on this bro, thank you. Very informative and easy to understand!
Cheers Micah, glad it helped!
This is a good tutorial and I learned a lot, however I’m trying to create a blue-skinned person, with black hair and glowing red eyes, and it really screws up on me 🙁
Any advise?
I acknowledge the difficulty of that prompt with SD. I think you can get what you want with SDXL which will be more responsive to natural language
This is the amazing information I was looking for. Thank you so much for your time and effort in making this available to us who are just starting and are using underdog GPU ( AMD).
Hey John, glad it was helpful!
Estoy sin palabras ya había llegado a estas conclusiones utilizando chatGPT, pero aquí están mejor explicadas y los ejemplos ilustran mejor la idea. Gracias por tomarte el tiempo y por compartirlo