Amongst AI art generator websites, Getimg.ai stands out for its good branding. I've also seen it mentioned on the Stable Diffusion subreddit quite a few times, so I knew I had to try it at one point.
Getimg.ai not only comes with an image generator, but also comes with a suite of AI image editing tools, all of which I'll cover in this review.
Under the hood, Getimg.ai uses Stable Diffusion to generate images. This means you can use various Stable Diffusion models to generate in different styles, as well as advanced features such like inpainting and ControlNets.
You can download a Stable Diffusion WebUI and generate images for free on your own computer, but this is more complicated than using a website.
Getimg.ai lets you skip the long setup and learning process of using a WebUI.
With that in mind, one of the things I'm going to really focus on is ease-of-use, and user experience for somebody who has never used these apps.
Features
Here's a full bulleted list of Getimg.ai's feature set:
- Text-to-image: generate images from text prompts
- Image-to-image: generate images from a starting image
- DreamBooth: Create your custom AI model
- Inpainting: edit images with only text
- Outpainting: expand an image by generating outside its borders
- Instruct Pix2pix and Find and Replace: edit images using language.
There's many cool items here. Most image generation websites don't have DreamBooth, which lets you train your own model (I have a DreamBooth guide on training a custom model on your face for free here).
I've noticed sites charging upwards of $30 for training a single DreamBooth model. Getimg.ai lets you train 2 on their cheapest plan, which I'll get to in a bit.
The Basics: AI Generator
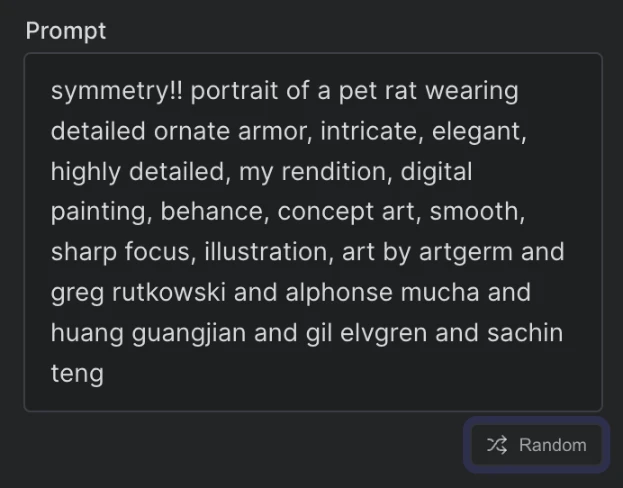
After you register an account, you see a blank screen, a field to enter to prompt, and some settings.
The prompt field says: "Describe something you'd like to see generated. Experiment with different words and styles…" Not too much handholding huh?
Thankfully, there's a little random button that generates a (presumably good) prompt for you.
The default setting is 4 images generated per button click, but this can be changed. I click "Generate" and get my first results:
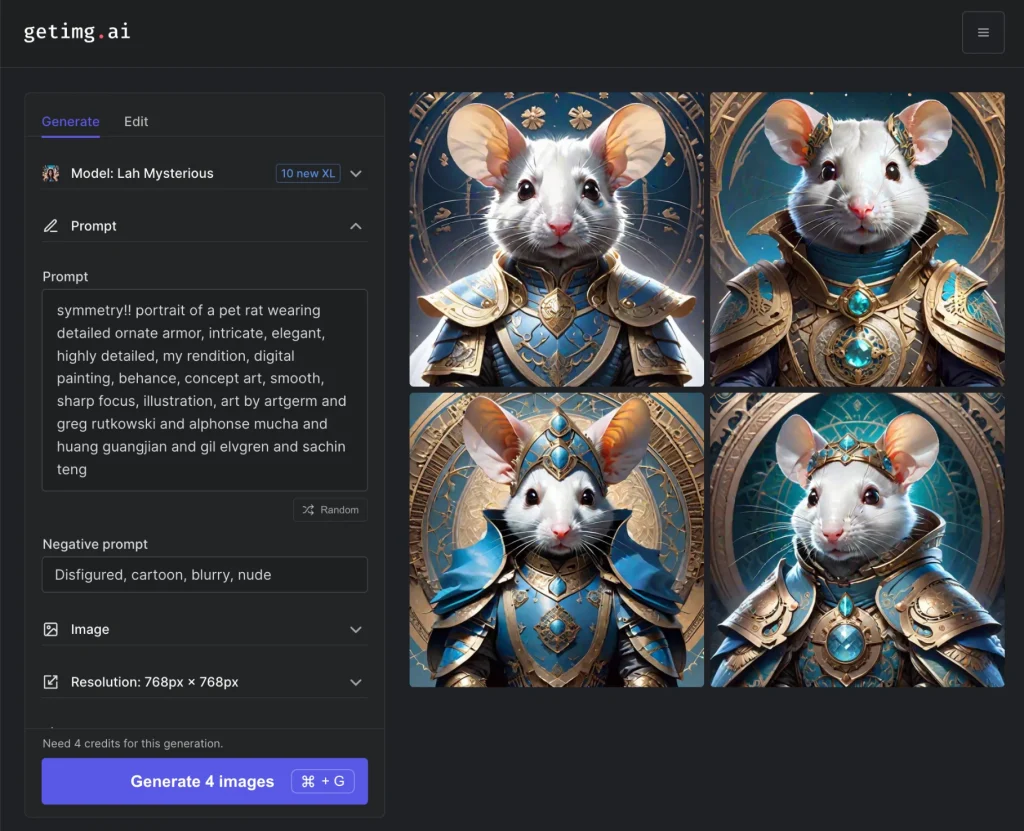
Model selection
We are in the SDXL era.
No idea what that means?
StabilityAI's partner Runway ML released Stable Diffusion v1.5 in Oct 2022. People used it as a base to create models that could generate various styles and content. Collectively, these custom models are known as Stable Diffusion 1.5 models.
SDXL is the newest base model, released on July 26, 2023 (in-between there was also Stable Diffusion v2.0 and Stable Diffusion v2.1, but these models were never popular because they were perceived as worse than the v1 models).
Compared to Stable Diffusion v1.5, SDXL creates images with higher quality and detail, and has more prompt nuance.
Model trainers have largely turned their attention to SDXL. Even though SD 1.5 models will be around for a while, I believe we will slowly move to using SDXL models only as the amount of custom models catch up.
Even though SDXL's default resolution is 1024x1024, Getimg.ai generates SDXL images at a default resolution of 768x768.

People talking about Stable Diffusion who have never tried Stable Diffusion will usually bring up models that nobody uses. When I see models that are known for being good, I feel reassured.
Getimg.ai does a good job of including these good models. The model selection is quite balanced, including a good mix of realism, semi-realism and anime models. It also includes legacy models that were once popular, but have largely fallen out of use like Arcane Diffusion, Ghibli Diffusion, and Openjourney.
You can trust really somebody when they recommend Dark Sushi Mix.
Me
I was pleasantly surprised too, to see models that I've never heard of before. The takeaway is that the Getimg.ai team is adding models fairly quickly and they know which ones are popular.
AI Canvas
AI Canvas includes a file system. Canvases are automatically saved so you can come back to them later.
So what is the Canvas? It's a hybrid of outpainting and various AI image editing tools.
Outpainting Tab
Outpainting is lets you expand an existing image by generating outside its borders.
Overall, I thought this feature was visually well designed, but feels clunky and I don't see myself using it. For example, you can drag the outpainting box so that it is not a square: I thought this would let me expand the image in multiple directions. When I tried it however, it just produced distorted images.
Edit Tab
The canvas also has an edit feature with 3 models: Instruct Pix2Pix, Find and Replace and Face Enhancement.
Instruct Pix2Pix lets you use natural language to change your pictures. For example, I generate an image and then use Instruct Pix2Pix to prompt: "she's wearing a necklace and large earrings" (original prompt: "woman with black hair, masterpiece" with AbsoluteReality v1.8.1 model).

Find and Replace is similar, but it looks for something specific to replace with something else. Here's my attempt to find "black hair" and replace it with "blonde hair"

Finally, there's Face Enhancement. This is not a great feature. It's based on Face Restoration, a Stable Diffusion feature that nobody really uses anymore, because there's a much better option - that Getimg.ai includes as well. See the discussion of Hires Generations below.

Overall, I though the Edit tab worked much better than the Outpainting tab, so it's a shame that the feature isn't emphasized and there aren't any tooltips that do a good job of educating the user what it does.
Image Editor
The image editor lets you upload any image or use any image you've previously generated with Getimg.ai (all images are stored in the Gallery), and use various AI tools to edit them.
If you open the "Advanced Settings" tab, you'll see this runs into the same limitation as outpainting: there are barely any models you use!

Inpainting
Inpainting lets you paint over a section of the image to create a mask, and then re-generate that area. Some blending of that area and the background is applied, so that area does not stand out too much. Here's what it looks like:

Sketch to Image
Sketch to image lets you draw on top of images and then regenerate them. This feature worked quite well.

Blend to Image
Add images then blend them in to match the background. This doesn't preserve anything, but generations an entirely new image. You can set the prompt strength.
I this example I uploaded two images. Getimg.ai lets you remove the background of any image, so I did that with the dog in the foreground.

I think the blending is quite well done. You can turn the strength lower to preserve the identity of the foreground and background.
Replace Background
This one replaces the background with your prompt. It did a surprisingly good job of creating a different ground and background in this example:

I was very happy with the results I got from the AI Image Editor. My one comment here is I wish there were more instructions/tooltips/videos that explained how you should use these tools.
Pricing Plans and Paid Features
The default setting is 4 generations at once, and generations cost 1 credit each.
You get 100 free images/credits when you first sign up.
The plans are as follows:
- $12/mo for 3000 images
- $29/mo for 12,000 images
- $49/mo for 24,000 images
- $99/mo for 60,000 images
For a little context as to how much 60,000 images really is: I've been using Midjourney since June 2022, and I consider myself a power user. I have a total of 22,486 Midjourney "jobs".

Now, a Midjourney job can be a generation of 4 images, or it can be an upscale. So let's say 80% of my jobs were image generations, and the rest were upscales. That's ~70,000 images across the span of a year and a half.
At 60,000 images/mo, you're looking at industrial use.
On the pricing page, you'll notice that after the basic plan the features don't change much.
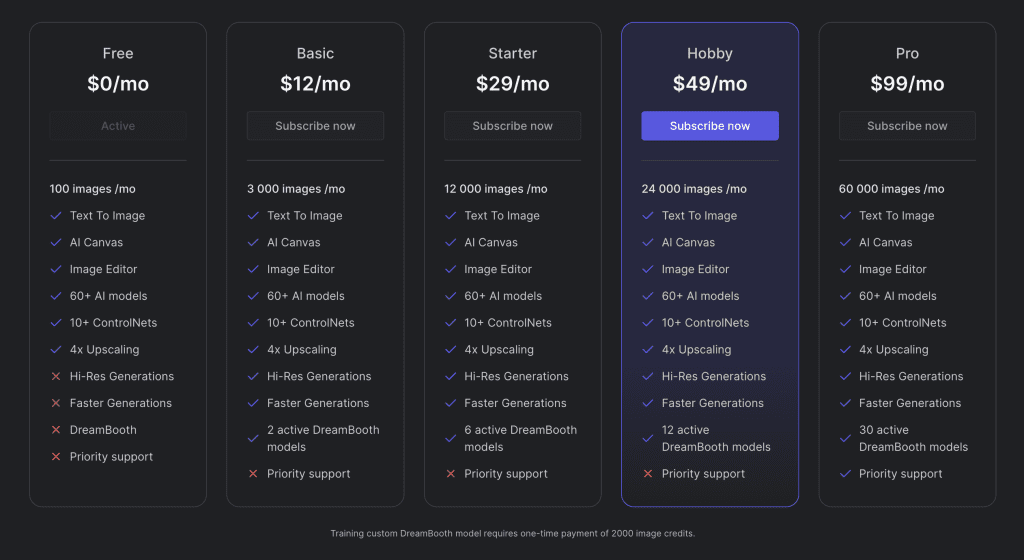
The only things you're missing out on the free plan are Hi-Res Generations, Faster Generations, DreamBooth and Priority Support. Let's get into each of things and see if they actually matter.
Hi-Res
Hi-Res is actually is big deal with image generation. In my Stable Diffusion best settings guide, I wrote that "The greatest impact setting you'll use is the Hires. fix" (Hires. fix is the Stable Diffusion feature that is used under the hood for Getimg.ai's Hi-Res generations).
This will not only upscale your images, but also greatly improve their quality. Let's take a look at an example:

Faster Generations
"Faster generations" is a bit of a misnomer. When I tested this on the $12/mo Basic plan, I noticed that your generations do not become noticeably faster, but you can generate many more images at once.
On the free plan:
- Generations took anywhere from 5-20 seconds
- Generate 4 images at once
On a paid plan:
- Generations took anywhere from 5-10 seconds
- Generate 10 images at once
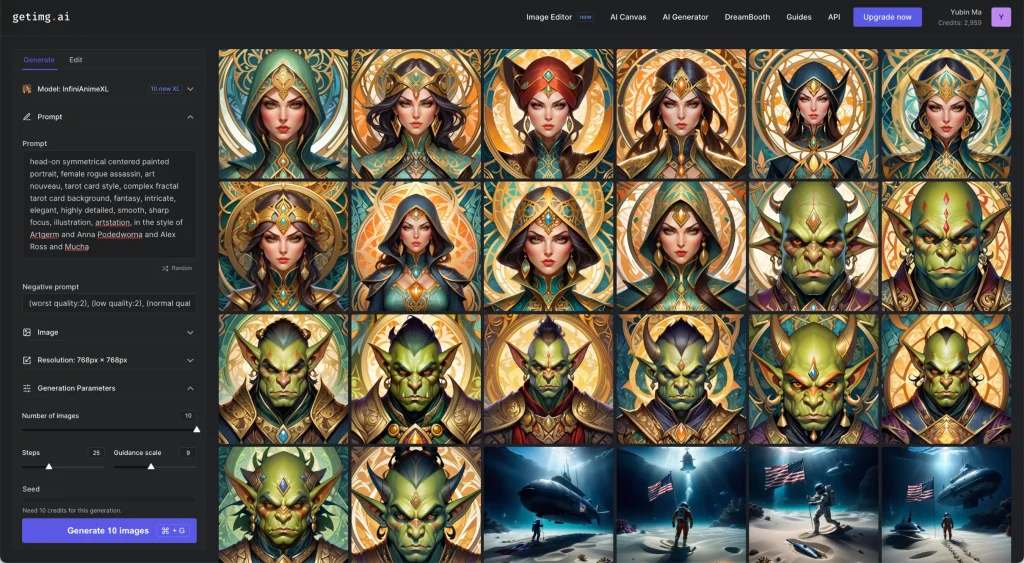
It's really great for testing an idea or prompt. I could speedrun through generations at a scale that I haven't experienced before. For comparison, Midjourney generates 4 images at once. If you run Stable Diffusion locally, you would use batch size/batch count to achieve this, and it would take a much longer time to generate.
This will deplete your credits pretty fast though. 3000 images on the $12/mo plan means 300 generation clicks if you're generating 10 images at once!
Getimg.ai Alternatives
Getimg.ai VS Midjourney
At the beginning of this Getimg.ai's $12/mo plan for 3000 generated images, I knew I had to try it. For comparison, Midjourney's cheapest plan ($10/mo) gives you only ~200 generations.

