What is a VAE?
A VAE (Variable Auto Encoder) is a file that you add to your Stable Diffusion checkpoint model to get more vibrant colors and crisper images. VAEs often have the added benefit of improving hands and faces.
If you're getting washed-out images you should download a VAE.
Sometimes you don't even realize what is 'washed out' until you see the alternative:


Technically, all models have built-in VAEs, but sometimes external VAEs will work better than the built-in one.
Best VAEs
While it seems like there are many VAEs out there, in reality 90%+ of VAEs are just renamed versions of the following:
- kl-f8-anime2 VAE (for anime)
- NAI/Anything VAE (for anime)
- vae-ft-mse-840000-ema-pruned (for realism)
Keep in mind, some models already have the VAE built-in. For example, Anything VAE is built into the Anything models, so applying it will not have any effect.
Comparison
Here's a comparison of these VAEs using the same model and same prompt:




And here's the same comparison using the Deliberate model for realistic images:



You can see kl-f8-anime2 VAE is the most vibrant, and vae-ft-mse-840000-ema-pruned VAE brings a bit of vibrance and sharpness to the image.
VAE Download Links
VAE can come in the older .vae.pt and .ckpt format as well as the newer .safetensors format, all of them will work.
NAI/Anything VAE


This one was initially released with NAI Diffusion, and comes bundled in Anything. Most of the anime VAEs out there (such as Orangemix VAE) are just renamed versions of this one.
kl-f8-anime2

AKA Waifu Diffusion VAE.
It's the most vibrant VAE out there, and sometimes I find it too vibrant for my needs.
This one was created by Hakurei by finetuning the SD v1.4 VAE on a bunch of anime-styled images, and released with Waifu Diffusion.
vae-ft-mse-840000-ema-pruned


For realistic models, but also suitable for anime/stylized models.
Created by StabilityAI and released with SD v1.4.
mse840000_klf8anime Test Merge

Experimental VAE made by merges the 2 VAEs above. More information on VAE merging below. I think the vibrance level on this one is really balanced.
NAI Blessed

Another experimental VAE made using the Blessed script.
Using VAEs
Note: Earlier guides will say your VAE filename has to have the same as your model filename. This is no longer the case.
Download any of the VAEs listed above and place them in the folder stable-diffusion-webui\models\VAE (stable-diffusion-webui is your AUTOMATIC1111 installation).
In the WebUI click on Settings tab > User Interface subtab.
Then under the setting Quicksettings list add sd_vae after sd_model_checkpoint.

Scroll to the top of the settings. Click Apply settings, and then Reload UI.
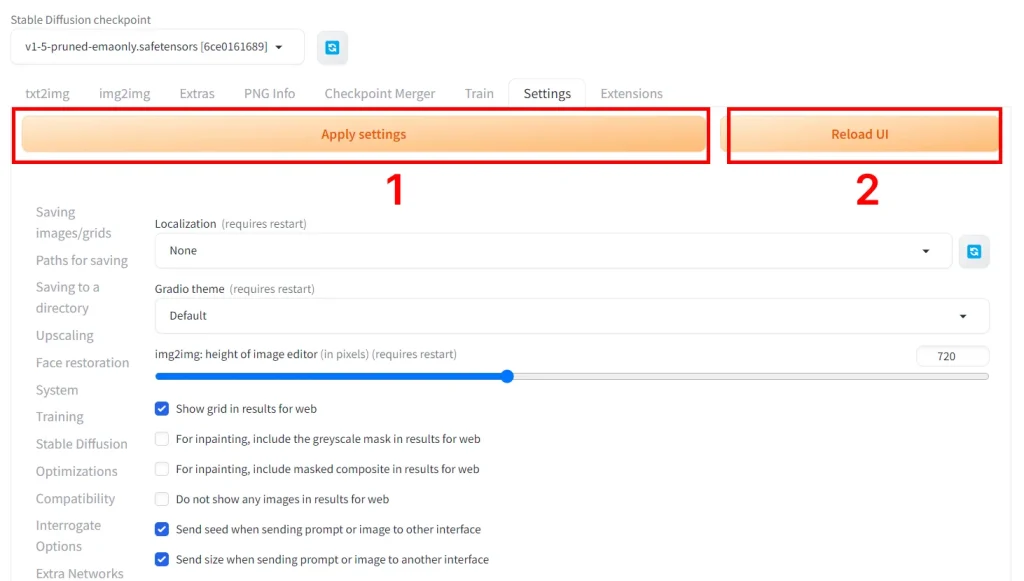
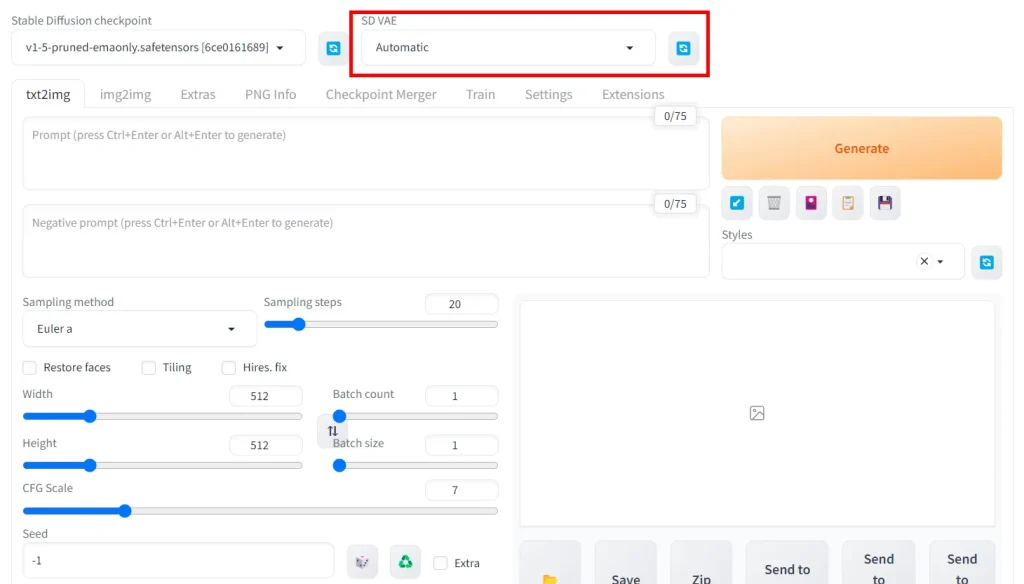
Now, you'll see an SD VAE dropdown at the top. Pick your VAE there. After downloading a new VAE and putting it in the VAE folder, you'll need to click the blue refresh button.
Merging VAEs
You can now merge VAEs with this extension:
http://github.com/ddPn08/stable-diffusion-webui-vae-merger
Install it from URL using the Extensions tab and follow the directions in the link.
How does a VAE work?
Image you have a set of 512x512 images, and you have to shrink them down to 256x256, then later return them to 512x512 with losing details.
You can train a neural network to do this.
The neural network can look at millions of images to calculate probabilities, so when it looks at the 256x256 images, it can make really accurate guesses about what the original 512x512 data was that was encoded in those 256x256 "latent" images.
Now let's say you have to do the same thing, but with 128x128 images.
So now you would train the neural network millions of 256x256 "latent" images, teaching the system to encode a ton of data into 128x128 pixels, so that later it can return them back to your larger 256x256 latent image.
And now you have a nifty two-step process that takes 512x512 images and compresses them into 256x256, then further compresses those to 128x128 latent images. And it can do it all in reverse, turning those 128x128 latent images into a near-approximation of the original 512x512 image. Magic.
Now do the exact same thing with 64x64 images.
Now your Neural Network can take any 512x512 image, send it through 3 layers of the VAE and make a 64x64 latent image. Then you can send that 64x64 latent image in reverse through those 3 layers of the VAE and get something kinda like your original image back out.
And that's a VAE, simplified.
FAQ
You don't actually need to install a VAE to run Stable Diffusion. Every model you use has a built-in VAE. You only need an external VAE when the colors are washed out.
The 3 most popular VAEs will cover almost all of the bases for you: download kl-f8-anime2 VAE and NAI/Anything VAE for anime, and vae-ft-mse-840000-ema-pruned for realism.

