If you're getting started with Local LLMs and want to try models like LLama-2, Vicuna, WizardLM on your own computer, this guide is for you.
One look at all the options out there you'll be overwhelmed pretty quickly:
You might be asking: which model will work best for me? What software is best for running them? Will they be able to run on my hardware?
We'll answer all these questions in this guide. We've written this guide to be as relevant as possible over the long run, so we will recommend models and UIs but not go very deep into them.
If you want to skip the details and get set-up fast, check out these guides:
Local LLMs
Large Language Models (LLMs) are a type of program taught to recognize, summarize, translate, predict, and generate text. They’re trained on large amounts of data and have many parameters, with popular LLMs reaching hundreds of billions of parameters.
The best of these models have mostly been built by private organizations such as OpenAI, and have been kept tightly controlled—accessible via their API and websites, not not available for anyone to download.
For a while, it was assumed that these organizations would dominate the LLM space simply because they could spend the most money to train the largest LLMs.
That changed with Meta's release of LLaMA (Large Language Model Meta AI).
LLaMA isn't truely open source - the license does not allow for commercial use.
But its released has heralded the open LLM renaissance, with researchers and hackers worldwide building on and improving LLaMA and other open source models.
Foundational (Base) Models VS Finetunes
Foundational models are generalized models that are capable of a wide variety of tasks, such as image classification, natural language processing, and question-answering.
The problem with foundation models is that they're incredibly expensive, and creating them is still limited to organizations that own or have access to supercomputers and can millions of dollars on training.
Fine-tuning these foundational models on the other hand, is very cheap and fast due to innovations such as LoRA which lets you "adapt" foundational models to particular tasks or domains.
Choosing a Model
Most popular models today are finetunes of LLaMA. Soon we'll be seeing more finetunes of LLama-2.
Models are generally compared by the number of parameters — where bigger is usually better.
LLama was released with 7B, 13B, 30B and 65B parameter variations, while Llama-2 was released with 7B, 13B, & 70B parameter variations.
- LLaMA: A foundational, 65-billion-parameter large language model
- Llama-2: Follow-up to LLaMA, a 70-billion-parameter large language model
Here are the best places to compare models:
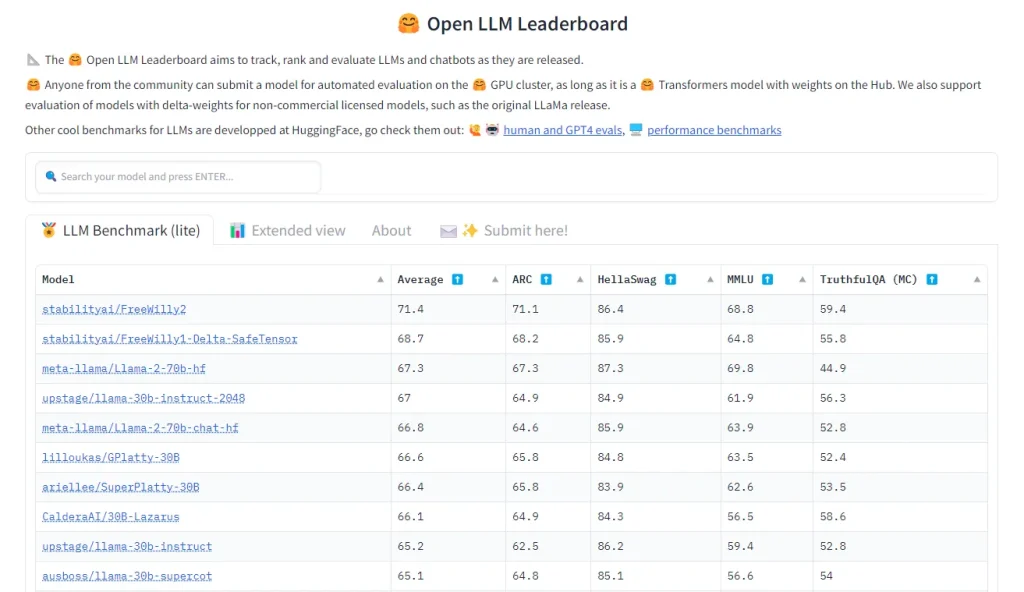
- Open LLM Leaderboard: Track Open LLMs as they are released and ranks them using a number of different popular benchmarks.
- Awesome LLM: A comprehensive resource covering research papers, tutorials, Open LLMs, and tools for running LLMs
- r/LocalLLaMA's Models: Community maintained list of popular models and download links
Evaluating model quality
HumanEval
HumanEval measures the model's coding ability. Introduced in Evaluating Large Language Models Trained on Code. It consists of 164 original programming problems, assessing language comprehension, algorithms, and simple mathematics, with some comparable to simple software interview questions.
EleutherAI's lm-evaluation-harness
A unified framework to test generative language models on a large number of different evaluation tasks. HuggingFace's leaderboard uses 4 of these tasks:
- AI2 Reasoning Challenge: a set of grade-school science questions.
- HellaSwag: a test of commonsense inference, which is easy for humans (~95%) but challenging for models.
- MMLU: a test to measure a text model’s multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more.
- TruthfulQA: a test to measure a model’s propensity to reproduce falsehoods commonly found online.
Which Quantization?
The goal of quantization is to decrease the file size while maintaining a non-proportional decrease in quality.
GPTQ
GPTQ quantization [Research Paper] is a state of the art quantization method which results in negligible perfomance decrease when compared to previous quantization methods.
As a general rule of thumb, if you're using an NVIDIA GPU and your entire model will fit in VRAM, GPTQ will be the fastest for you.
GGML
GGML is a machine learning library created by Georgi Gerganov. Gerganov also created llama.cpp, a very popular application created to run local LLMs on Mac, which uses the file format GGML.
If you're using Apple or Intel hardware, GGML will likely be faster.
The GGML library has undergone rapid development and experimented with a lot of different quantization methods. You'll notice there are many you can choose from:
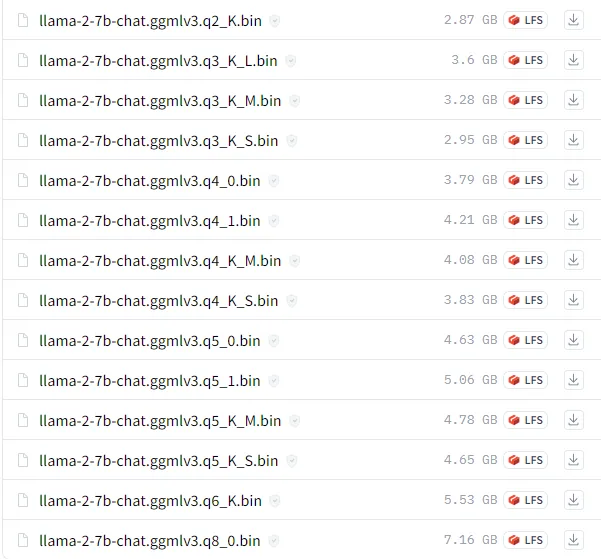
Llama-2-7B-Chat-ggml's quantizations
With the GGML format, quantization is written as Q<NUMBER>_<LETTERS AND NUMBERS>
The NUMBER is the number of bits. Q4 is 4-bit quantization. The more bits, the larger the filesize.
The letters afterward describe specific quantization approaches.
For example:
- Q5_K_M - Large, very low quality loss (this is recommended by a lot of people)
- Q5_K_S - Large, low quality loss
- Q4_K_M - Medium, balanced quality
Hardware Requirements
You can use these tables as requirement charts for LLaMA as well as all fine-tunes:
8-bit quantized models
| Model | VRAM Used | Minimum Total VRAM | Card examples | RAM/Swap to Load* |
|---|---|---|---|---|
| LLaMA-7B | 9.2GB | 10GB | 3060 12GB, 3080 10GB | 24 GB |
| LLaMA-13B | 16.3GB | 20GB | 3090, 3090 Ti, 4090 | 32 GB |
| LLaMA-30B | 36GB | 40GB | A6000 48GB, A100 40GB | 64 GB |
| LLaMA-65B | 74GB | 80GB | A100 80GB | 128 GB |
4-bit quantized models
| Model | Minimum Total VRAM | Card examples | RAM/Swap to Load* |
|---|---|---|---|
| LLaMA-7B | 6GB | GTX 1660, 2060, AMD 5700 XT, RTX 3050, 3060 | 6 GB |
| LLaMA-13B | 10GB | AMD 6900 XT, RTX 2060 12GB, 3060 12GB, 3080, A2000 | 12 GB |
| LLaMA-30B | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 | 32 GB |
| LLaMA-65B | 40GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000 | 64 GB |
What about all the different quantizations GGML has, like 5-bit quantization?
Unfortunately we don't have any benchmarks for these quantizations, as they're coming out so fast.
Your best bet is to check r/LocalLLaMA for anecdotal benchmarks.
Software for Running Models
We'll need a web interface to run our models. Here are the most popular options:
Oobabooga / Text-Generation-WebUI
Oobabooga's text-generation-webui is one of the most popular web interfaces, which is a program meant for hosting and running language models on your computer.
Kobold.CCP
A developer combined the best parts of llama.cpp and KoboldAI into Kobold.CCP, which also has the benefit of an easy one-click installer.
llama.cpp
A more optimized program for running language models, but on your CPU instead of your GPU, which has allowed large models to run on Mac. There are of course other differences but that is the main one that sets it apart from others.
KoboldAI
Another program/UI for text generation, but more focused on being a "game".
TavernAI
Another program/UI meant primarily for storytelling. An improved version of KoboldAI's "Adventure Mode", which is why they're often combined along with Pygmalion to create a more robust and realistic roleplaying experience.

