Getting started with local LLMs? Check out the beginner's LLM guide as well.
Meta has released Llama-2 and it is currently rated one of the best open source LLMs.
Because it is an open source model, we are waiting to see people build fine-tunes on top of it to improve performance even further.
Here's how to run Llama-2 on your own computer.
Install the Oobabooga WebUI
Install Build Tools for Visual Studio 2019 (has to be 2019) here.
Check "Desktop development with C++" when installing.
Download this zip, extract it, open the folder oobabooga_windows and double click on "start_windows.bat". This will take care of the entire installation for you.
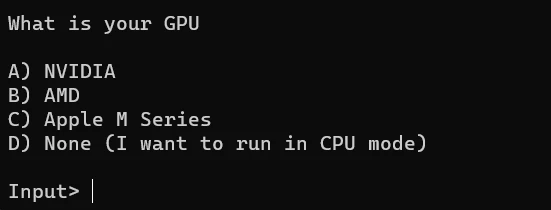
When prompted to, type the letter that corresponds with your GPU and press enter:
Wait for all the required packages to finish downloading.
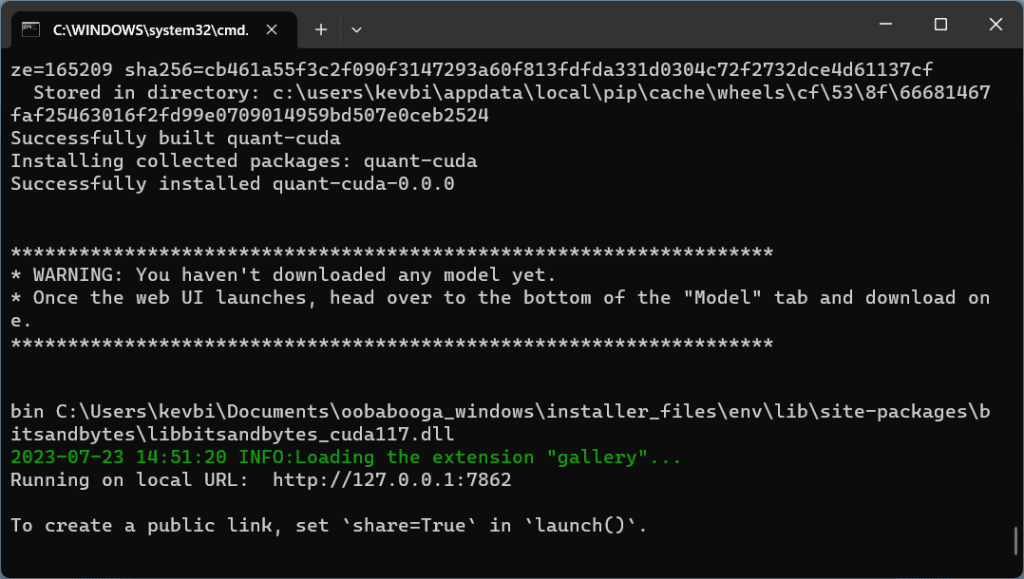
When you get the message Running on local URL: http://127.0.0.1:7860, go to this address and you will see the WebUI interface:
Download the model
First, decide on which model version you will use.
Here are the distinctions that matter:
Parameters: 7B, 13B or 70B
The more parameters, the higher quality output you get. However, the more parameters the higher the filesize and more performance requirements there are.
Standard or Chat
LLMs can be fine-tuned towards particular styles of output.
Llama-2 is the standard version of the model. Llama-2-chat is the fine-tune of the model for chatbot usage (will produce results similar to ChatGPT).
GPTQ or GGML
As a general rule of thumb, if you're using an NVIDIA GPU and your entire model will fit in VRAM, GPTQ will be faster. GPTQ Paper
If you're using Apple or Intel hardware, GGML will likely be faster. GGML is focused on CPU optimization, particularly for Apple M1 & M2 silicon.
Community members (such as TheBloke) has been tirelessly applying these quantization methods to LLMs in the Huggingface library.
More information on these model quantization formats:
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers is a research paper that outlines the details for quantizing LLMs.
- GGML relies on the same principles, but is a different underlying implementation.
Quantization
There are so many different quantizations now.
The GPTQ models below are all quantized to 4-bits, but the GGML models have a large number of different quantizations.
Highly recommended are:
- q4_K_S
- q4_K_M
- q5_K_M
| Model | Download |
|---|---|
| Llama 2 7B | Source - GPTQ - GGML |
| Llama 2 7B Chat | Source - GPTQ - GGML |
| Llama 2 13B | Source - GPTQ - GGML |
| LLama 2 13B Chat | Source - GPTQ - GGML |
| Llama 2 70B | Source - GPTQ - (GGML not out yet) |
| Llama 2 70B Chat | Source - GPTQ - (GGML not out yet) |
After you've downloaded the model, place it in the folder oobabooga_windows/text-generation-webui/models.
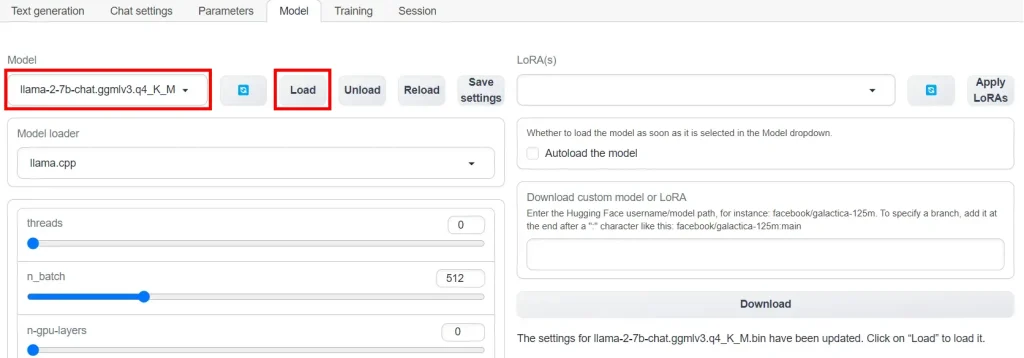
In the WebUI, go to the Model tab. Select your model in the Model dropdown, and then click the Load button.
Usage
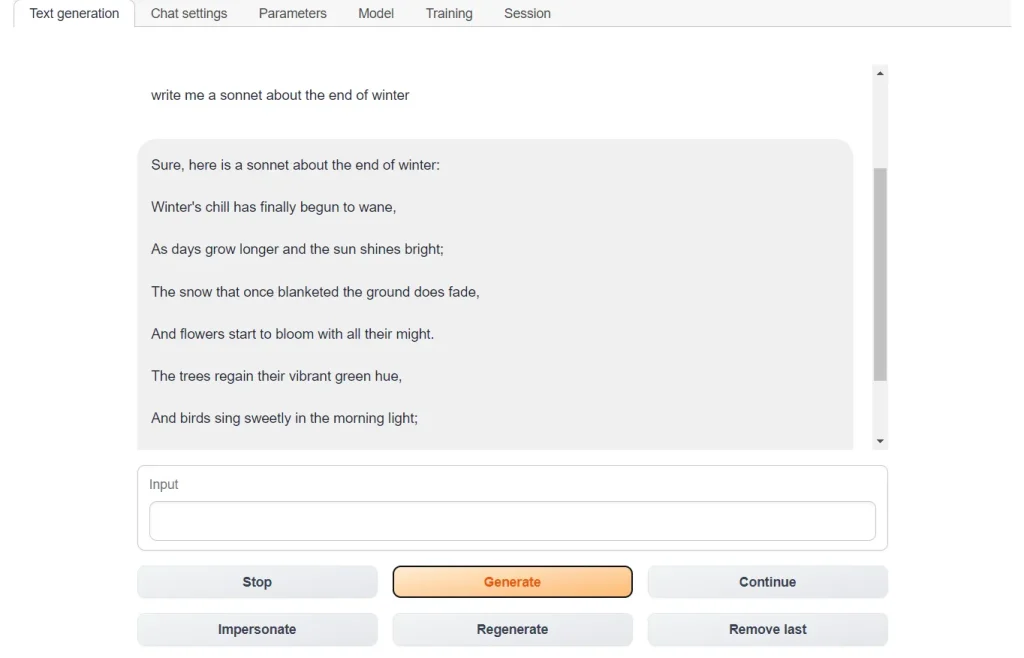
Go back to the Text Generation tab. Now you can start chatting by typing your prompts in the Input box and then clicking Generate.